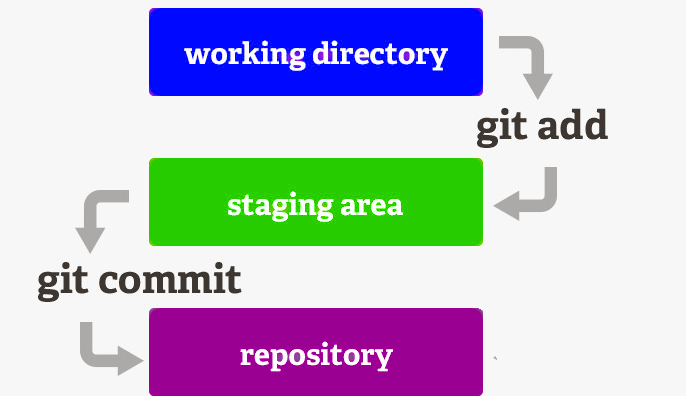
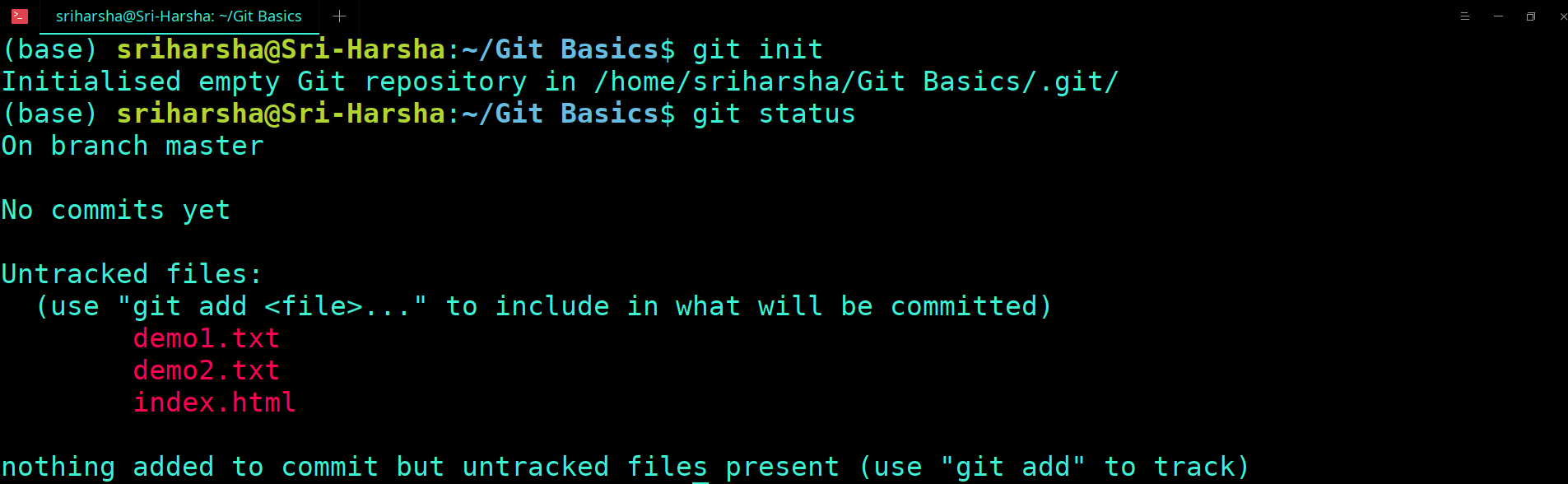
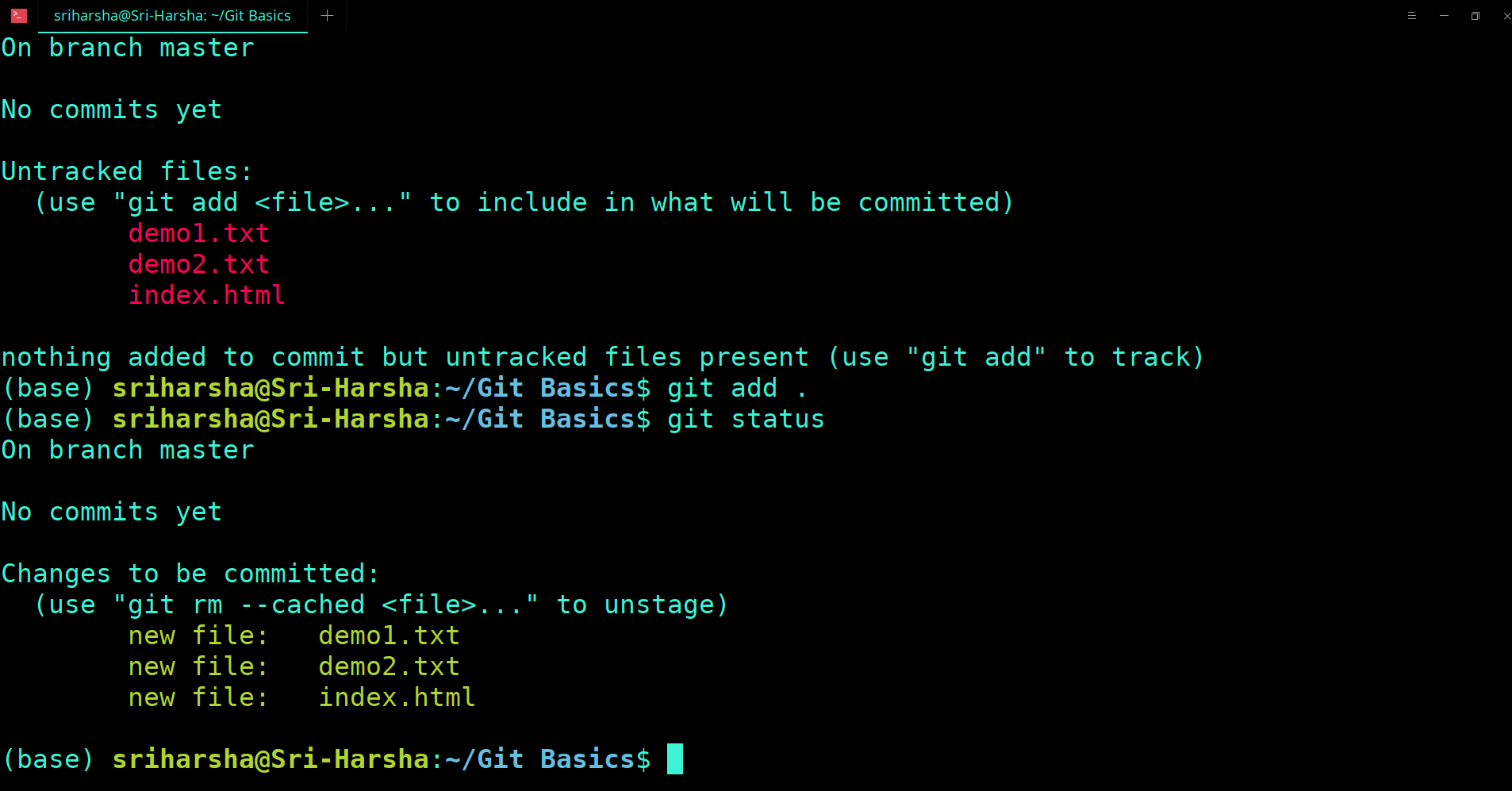
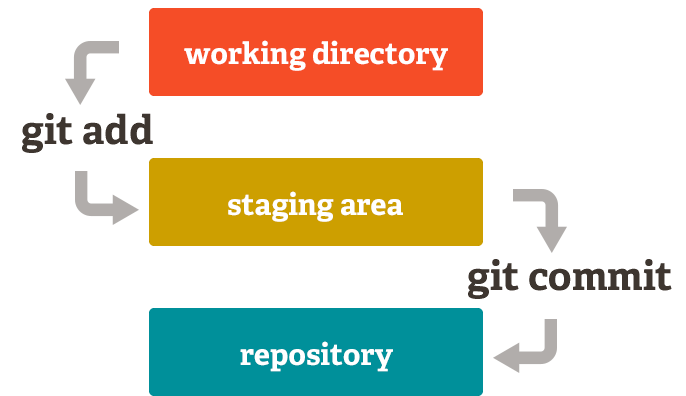
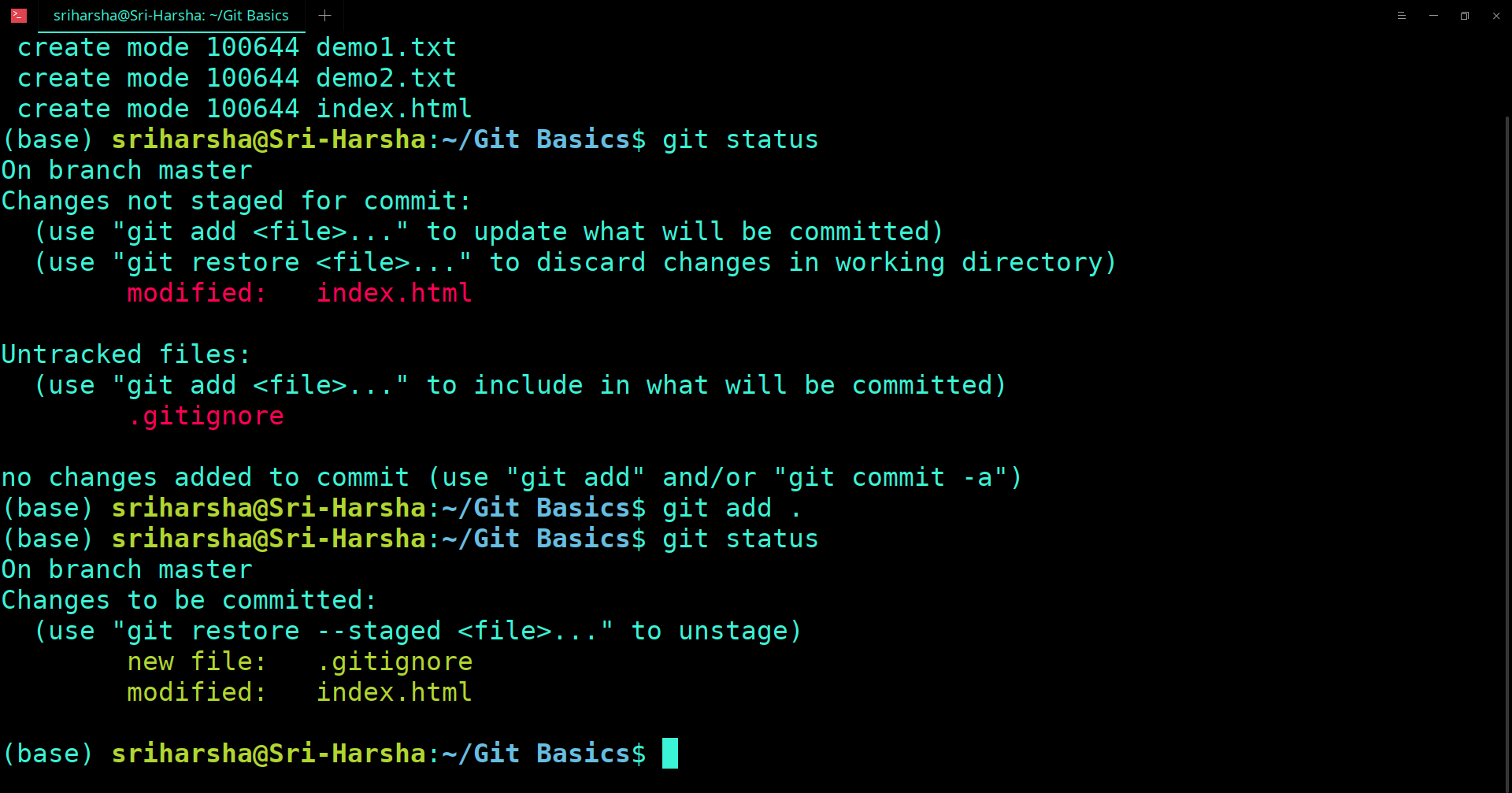
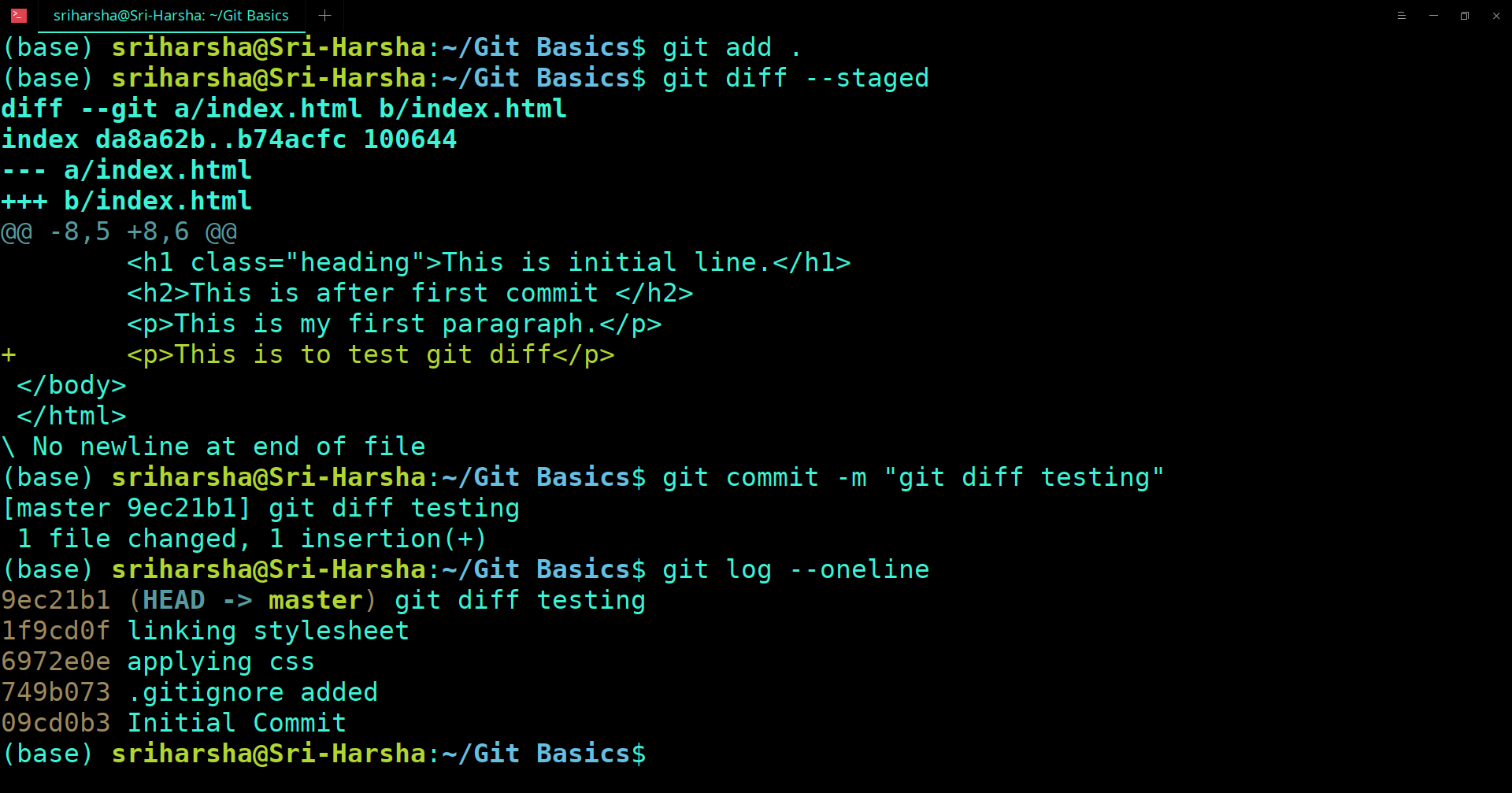
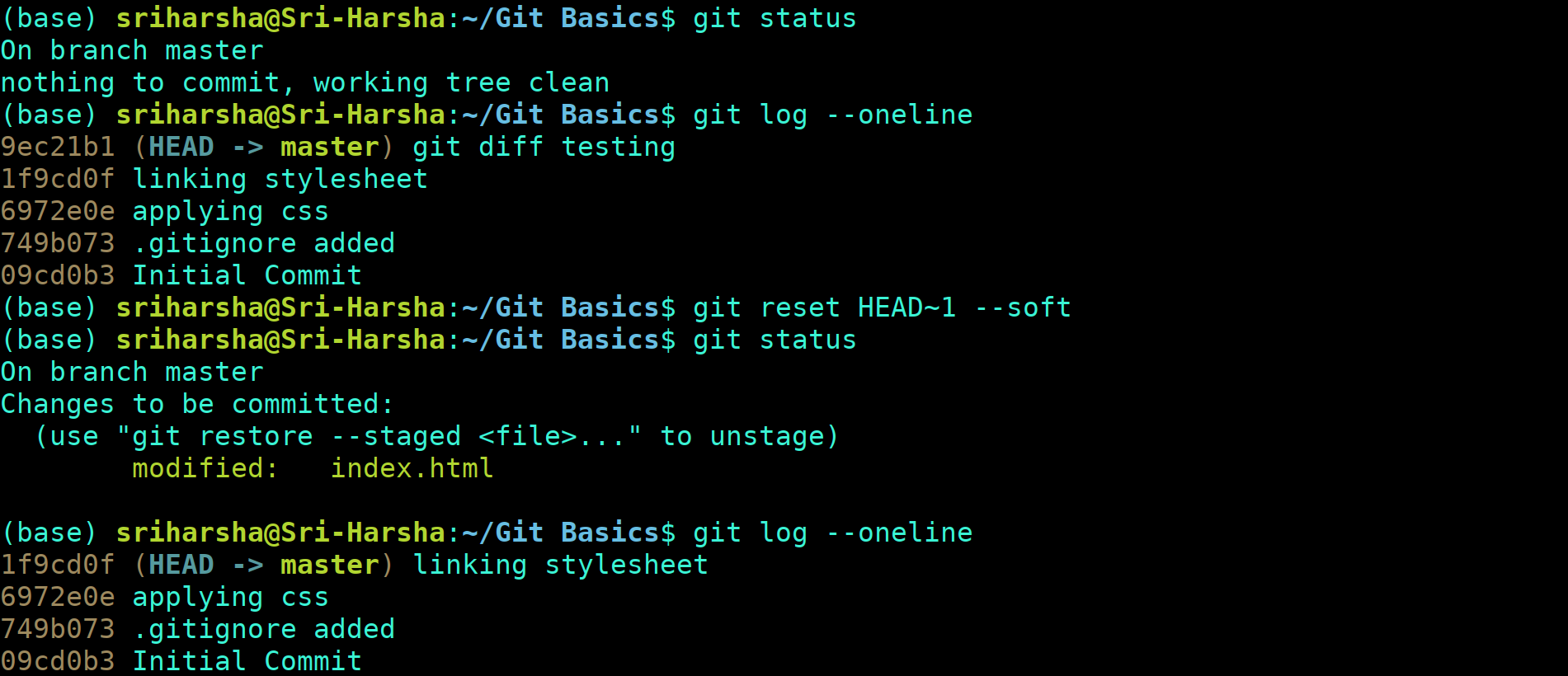
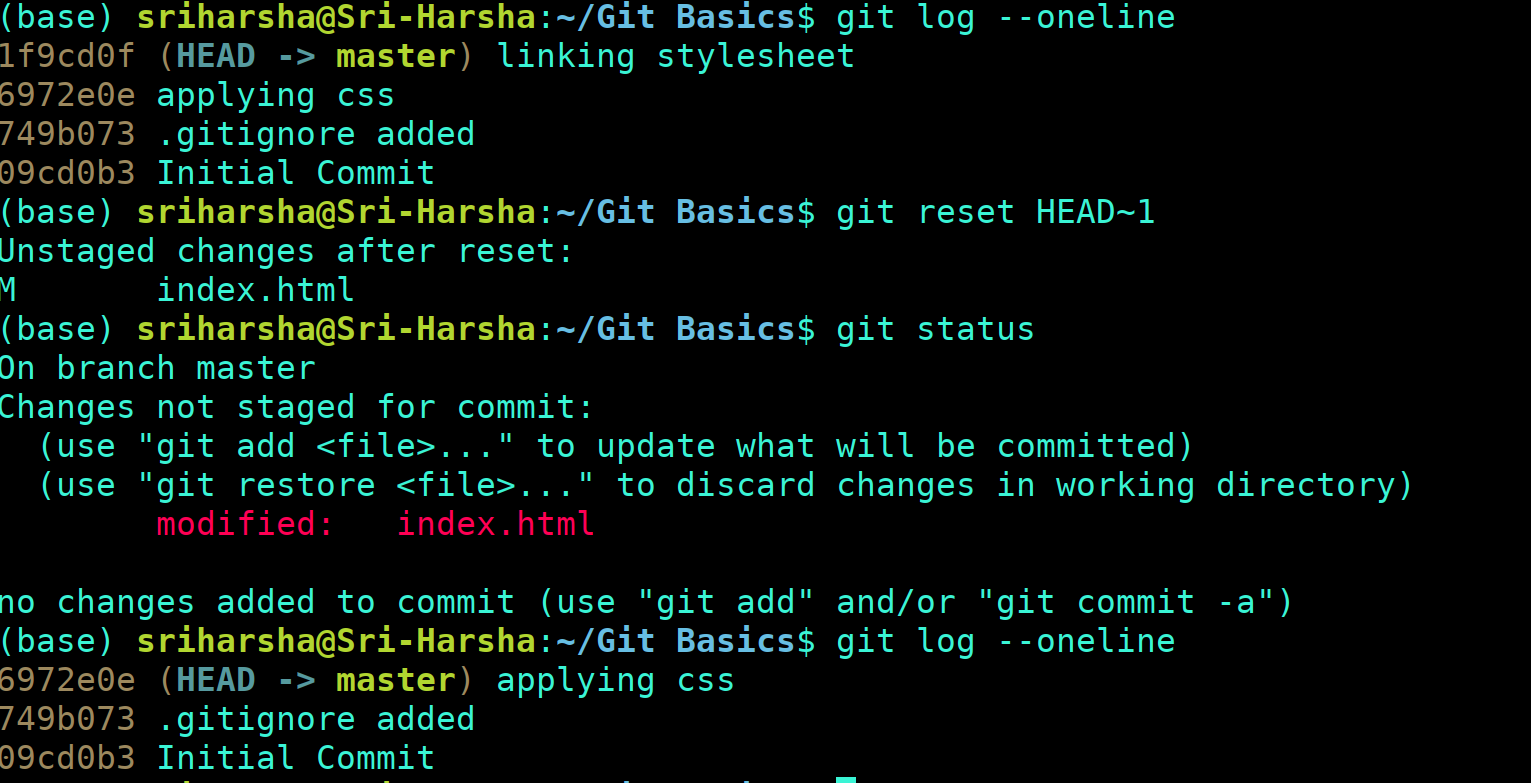
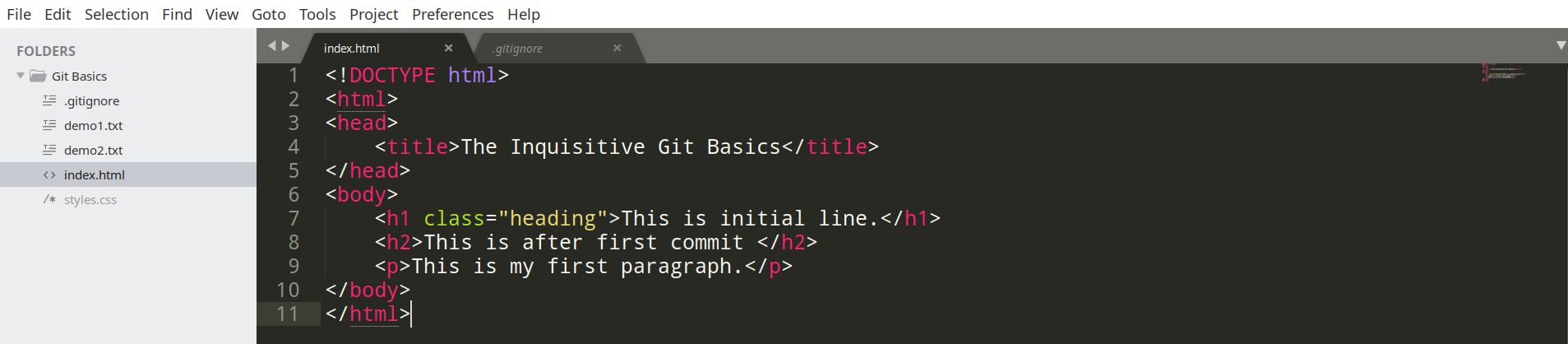
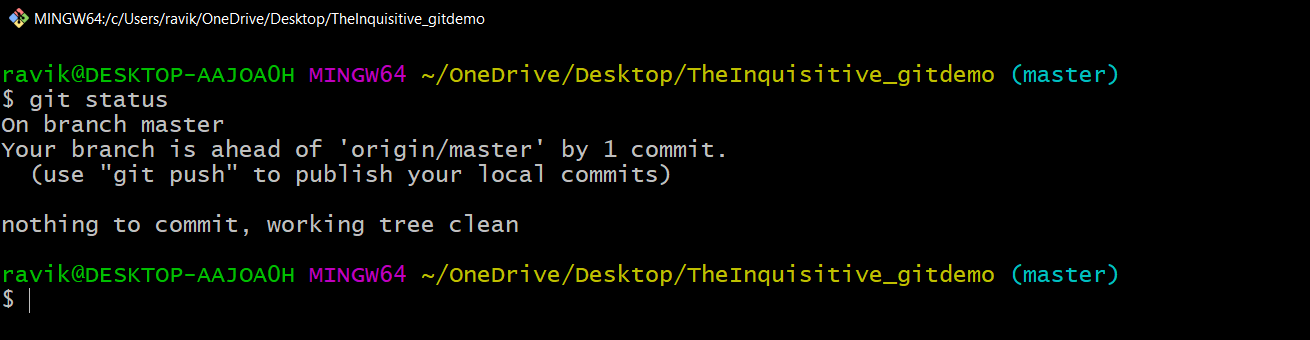
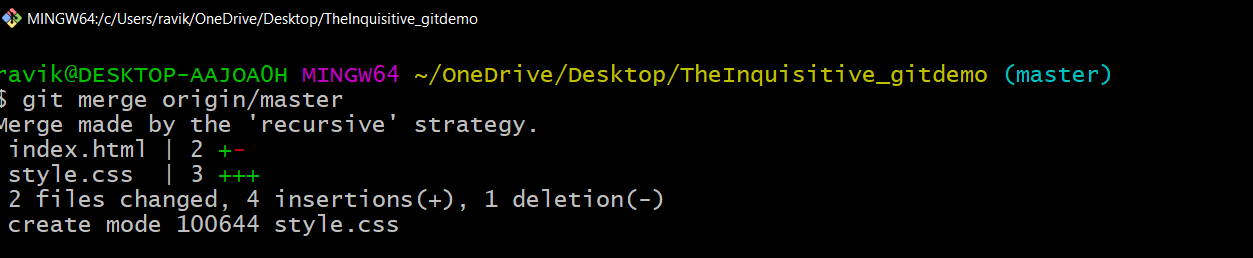
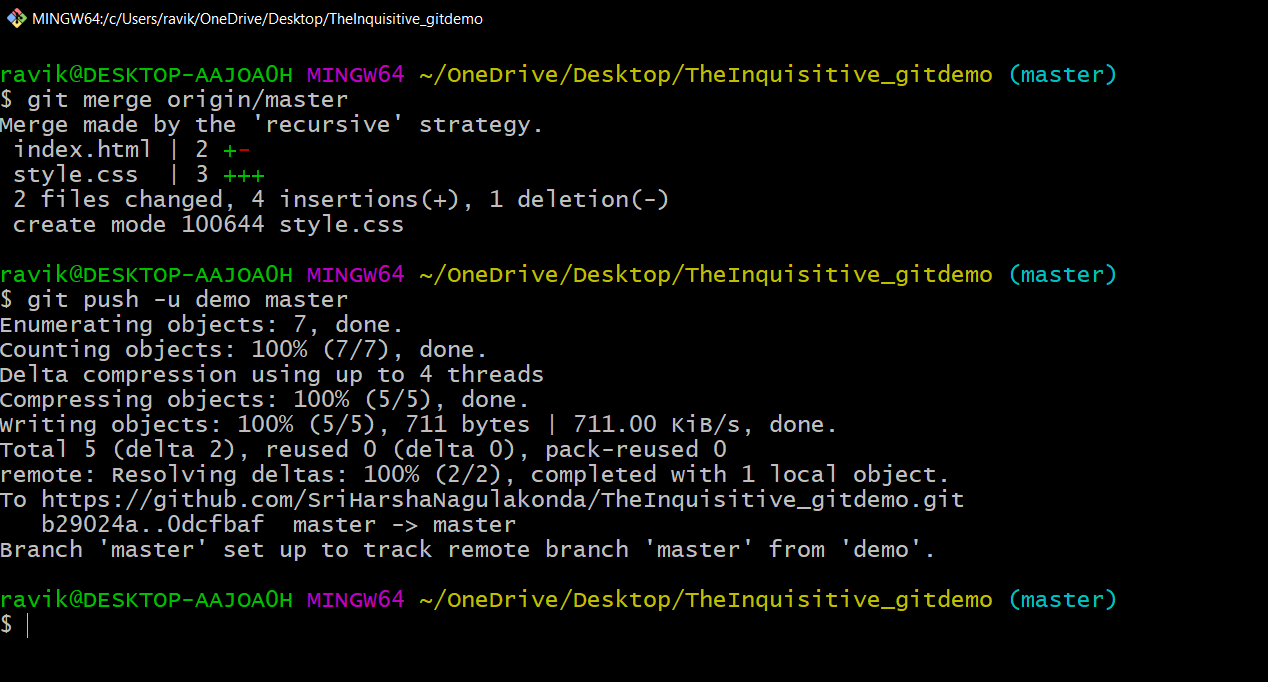
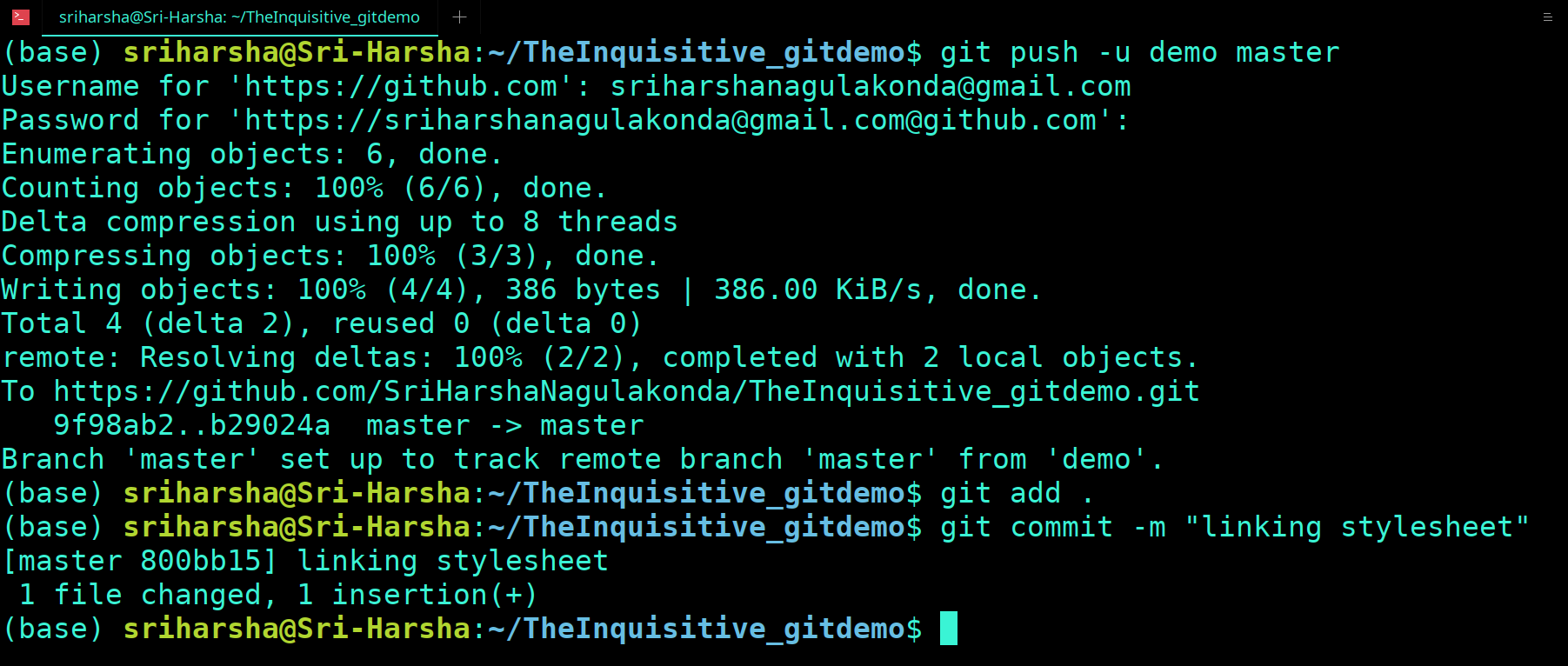
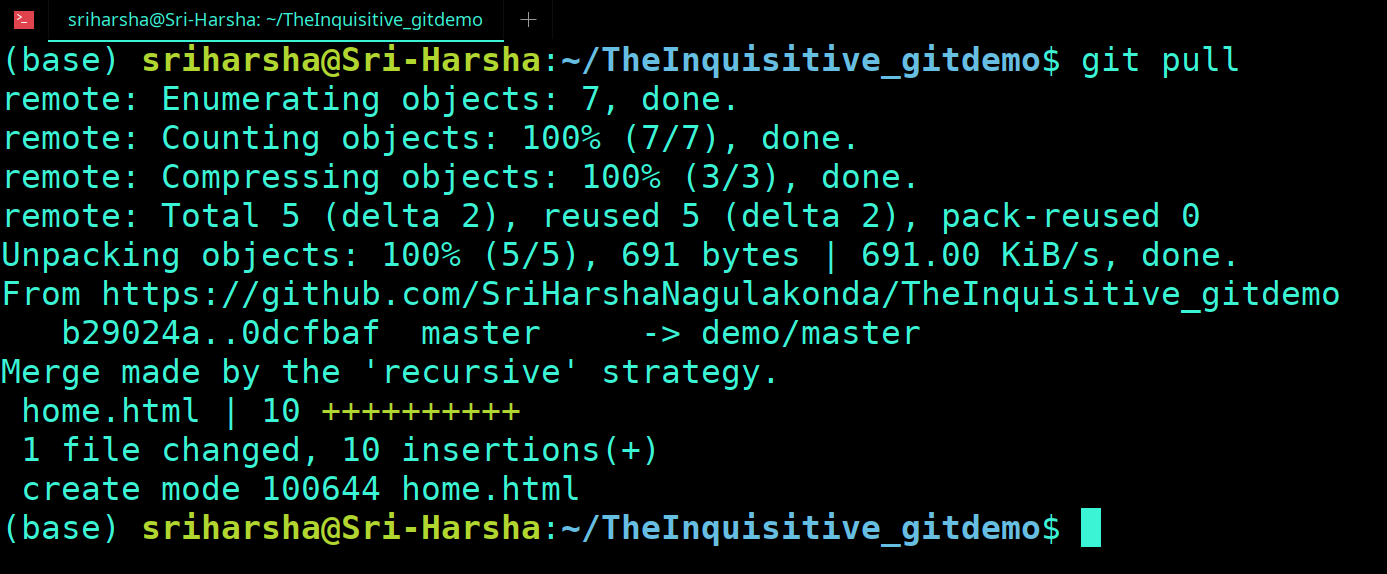
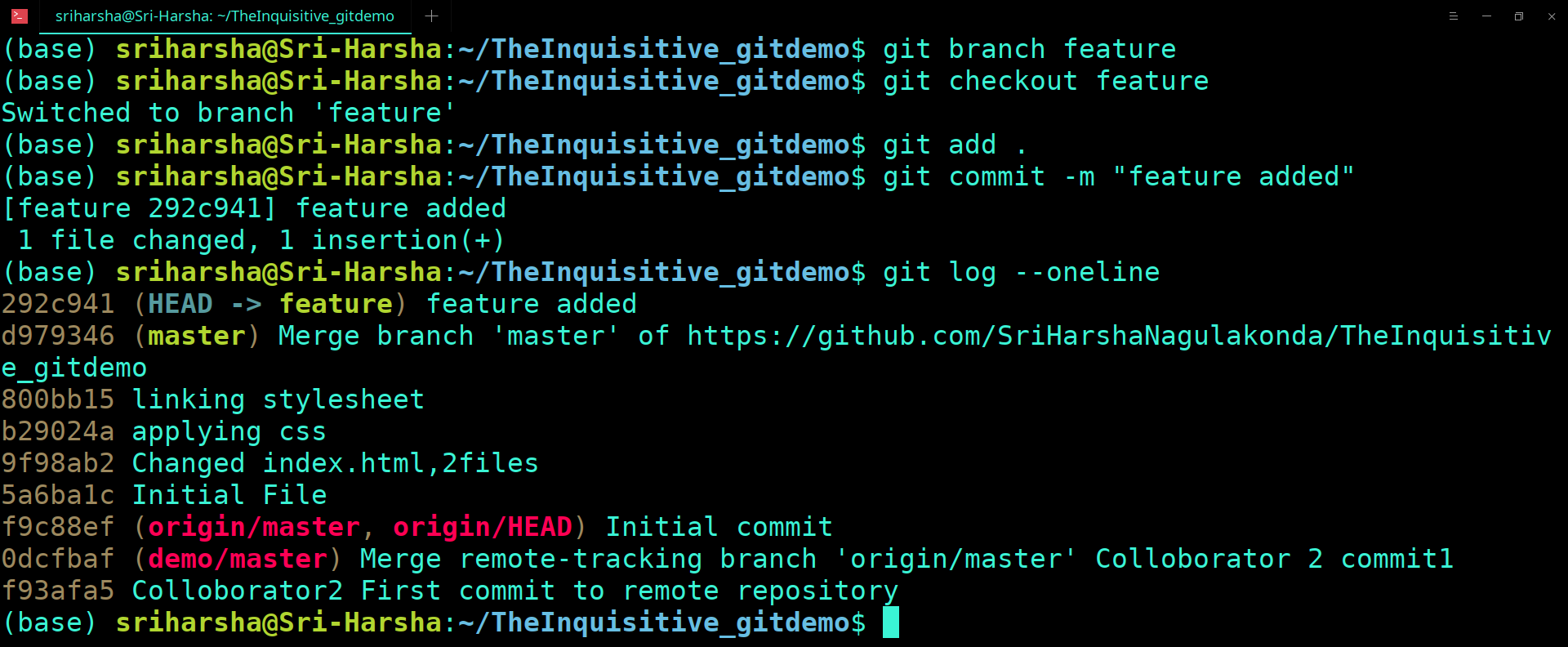
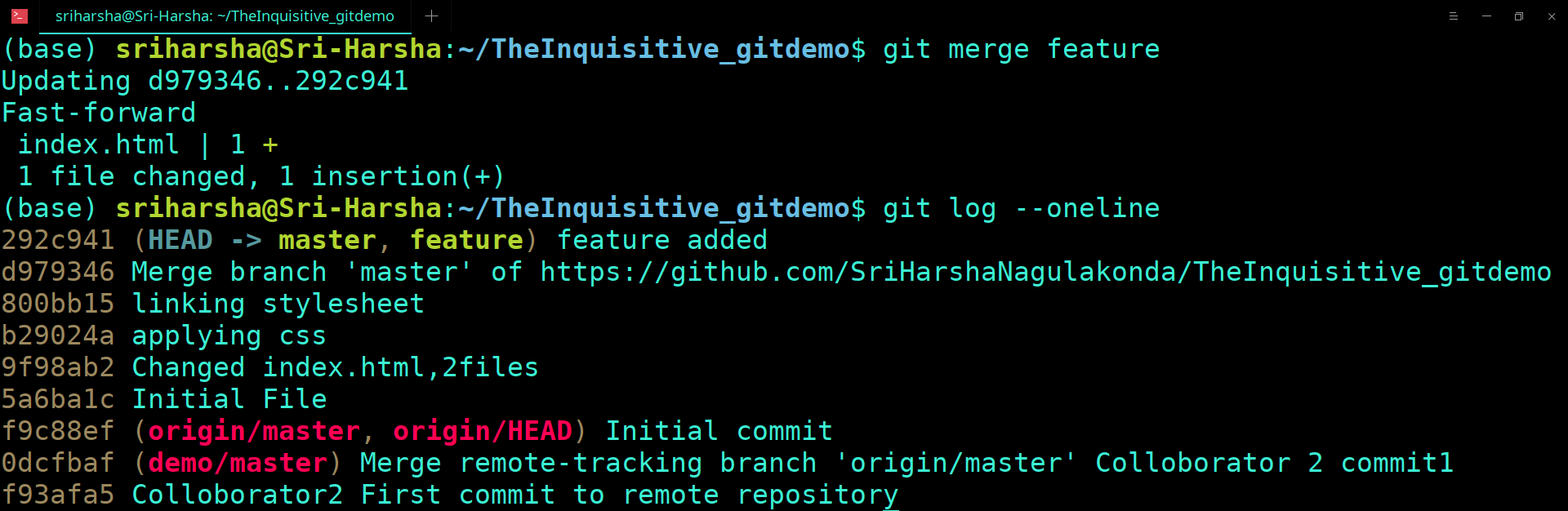
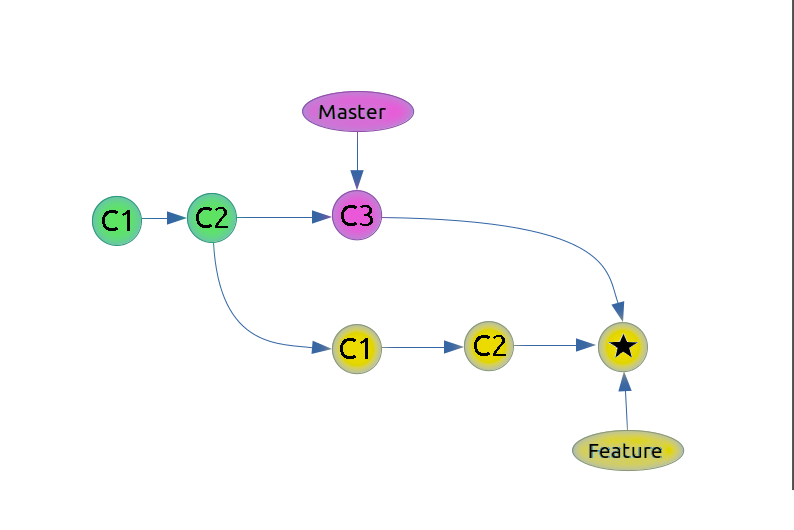
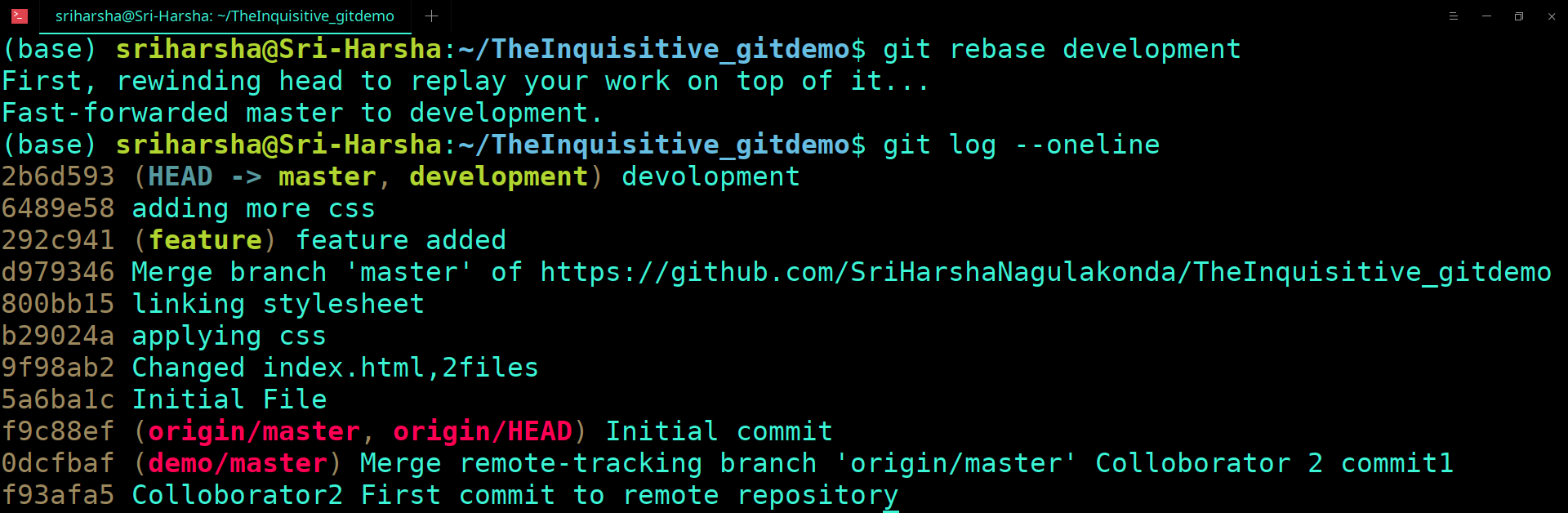
Before the version control system, developers in the team used the file system. In this system everyone needed to have multiple copies of the same file/folder to keep track of the changes they themselves and others were making. It was very difficult among the develgopers to update the files every time each developer made some changes. To overcome this issue, the Version control system was adapted.
GIT is a version control system (VCS). Before going into its depth, let’s understand an important concept, Version control.
What is Version Control and what is its purpose?
Version Control is a system that stores all the changes of a file or set of files as versions over time. Whenever we require a specific version, we can roll back to that particular version and access its files/folders. This helps in managing and tracking the file system.
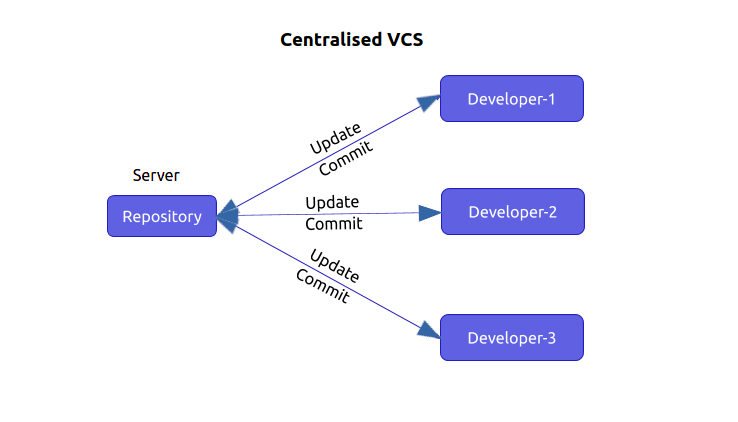
A centralized source has both a server and a client. The server acts like a master repository which contains every version of the code and all of its branches. The client side is like a local unit which communicates with the server and pulls all the code or the latest version of the required code from it. For any kind of project, generally the user or the client will have to get the code from the master repository or the server.
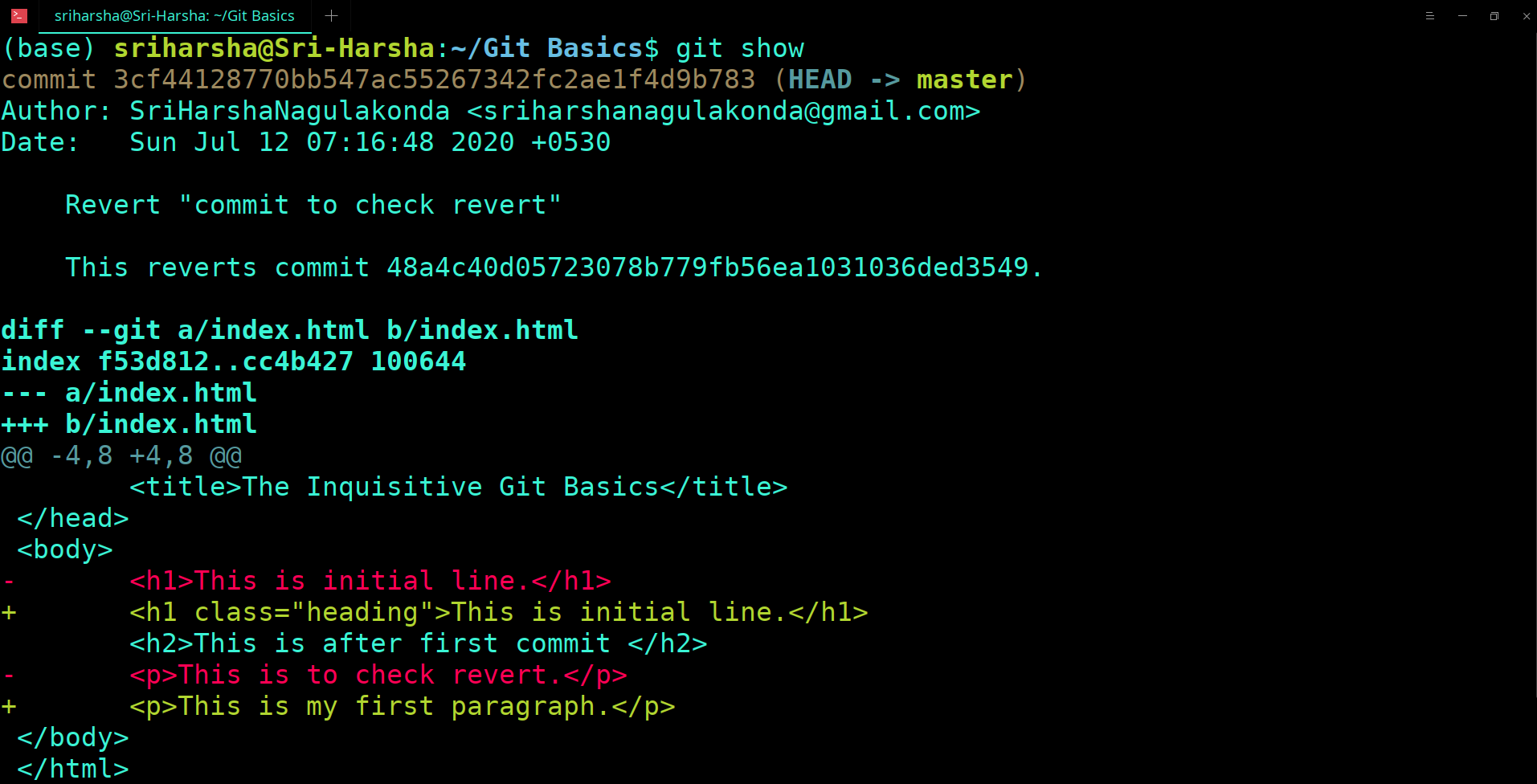
Once this communication is established between the client and the server, the latest version of the code will be available on the local machine and any changes can be made. Remember that these changes that you make are only made in your local machine which contains only a copy of the original code. In order to reflect the changes onto the master repository, one must 'commit' those changes. Committing a change is nothing but merging your own updated code into the server.
This model is said to be centralised because the main control remains at one central unit which is the server. Every time changes are committed by anyone to the source code it becomes a new version.
Hence, the basic flow of working involved in the centralized source control is getting the latest version of the code from the central repository to the local machine, making the required changes and committing them to the server.
Eg: SVN,CVS
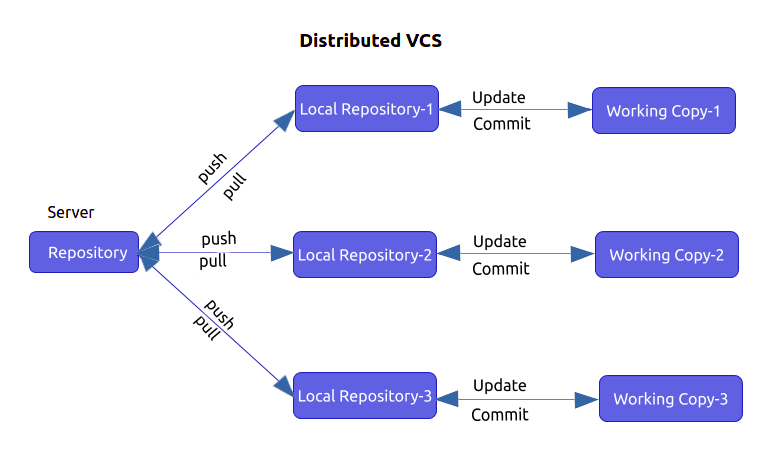
Unlike the Centralised VCS, in the distributed VCS, every developer or the user has their own local server which will contain a copy of the entire code, its history, its branches and its versions in it. In this way, every client or user can work locally though being disconnected, which is an advantage over the centralized source control.
When working on a project, you pull the code from the local server to your machine, then make your changes and commit them to your local server. At this point, your local repository will have ‘change sets‘ but the changes are not reflected in the master repository because the master repository has different 'change sets'. To commit the changes from the local server into the master repository, you have to issue a request to it. Then, the code will get updated in the master repository also. Getting a new change from a repository is called “pulling” and merging your local repository ‘set of changes’ is called “pushing“.
To summarize, in the distributed VCS model, changes are first committed to the local server or repository and then the ‘set of changes’ will be merged to the master repository.
Eg: Git, Mercurial, Bazaar…etc
Note: Distributed Version Control System also has the Central version/ Master branch but its functionality is different when compared with Centralised VCS.
GIT is a Distributed version control system. GIT is Open source software which helps in managing and tracking of the source code over a development phase of Software Development Life Cycle (SDLC). It can store the history of the content which might be a file or a set of files. Git provides collaborative changes among the developers.